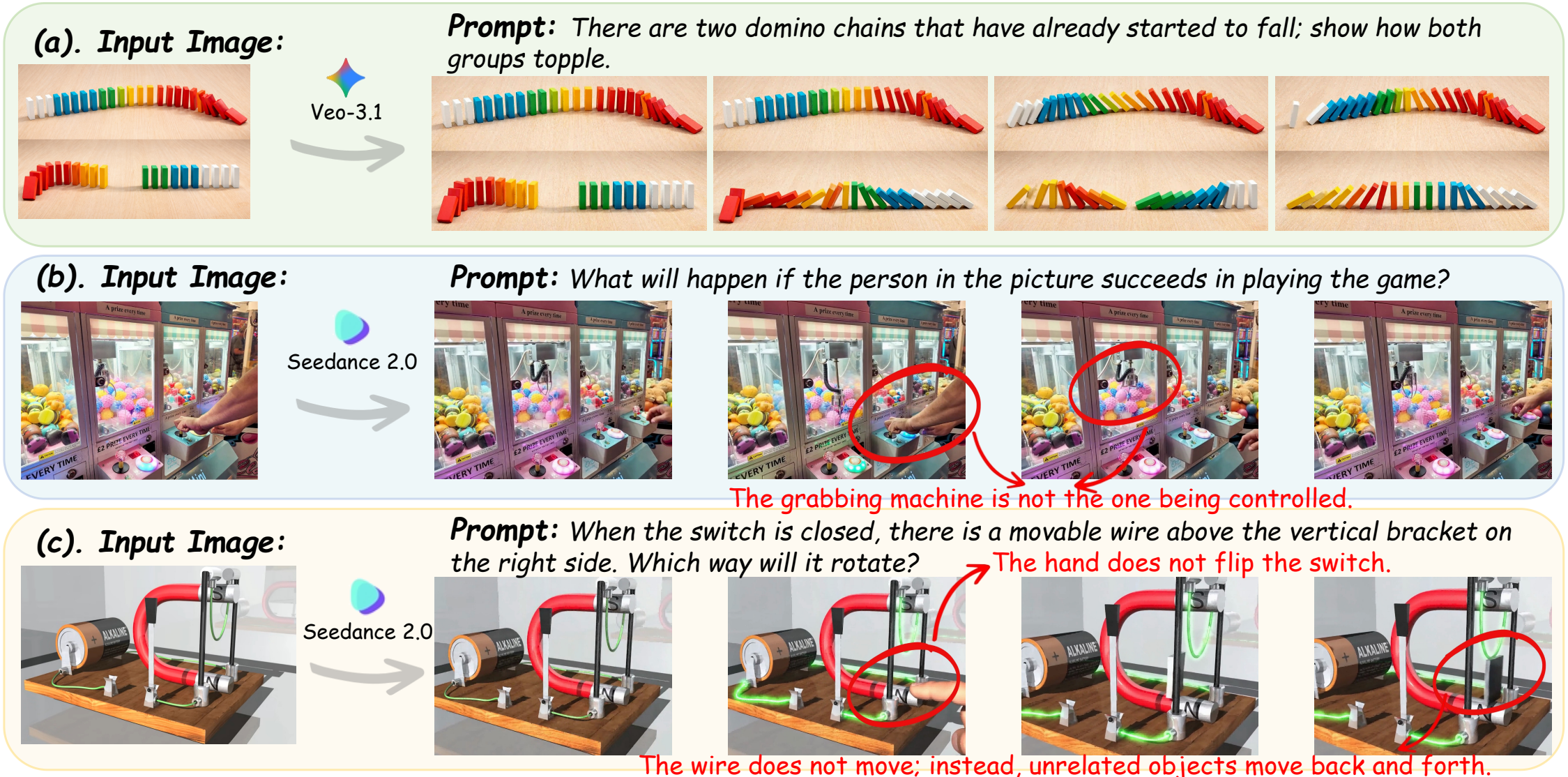
Commercial video generation systems such as Seedance2.0 and Veo3.1 have rapidly improved,
strengthening the view that video generators may be evolving into “world simulators.”
Yet the community still lacks a benchmark that directly tests whether a model can reason about
how an observed world should evolve over time.
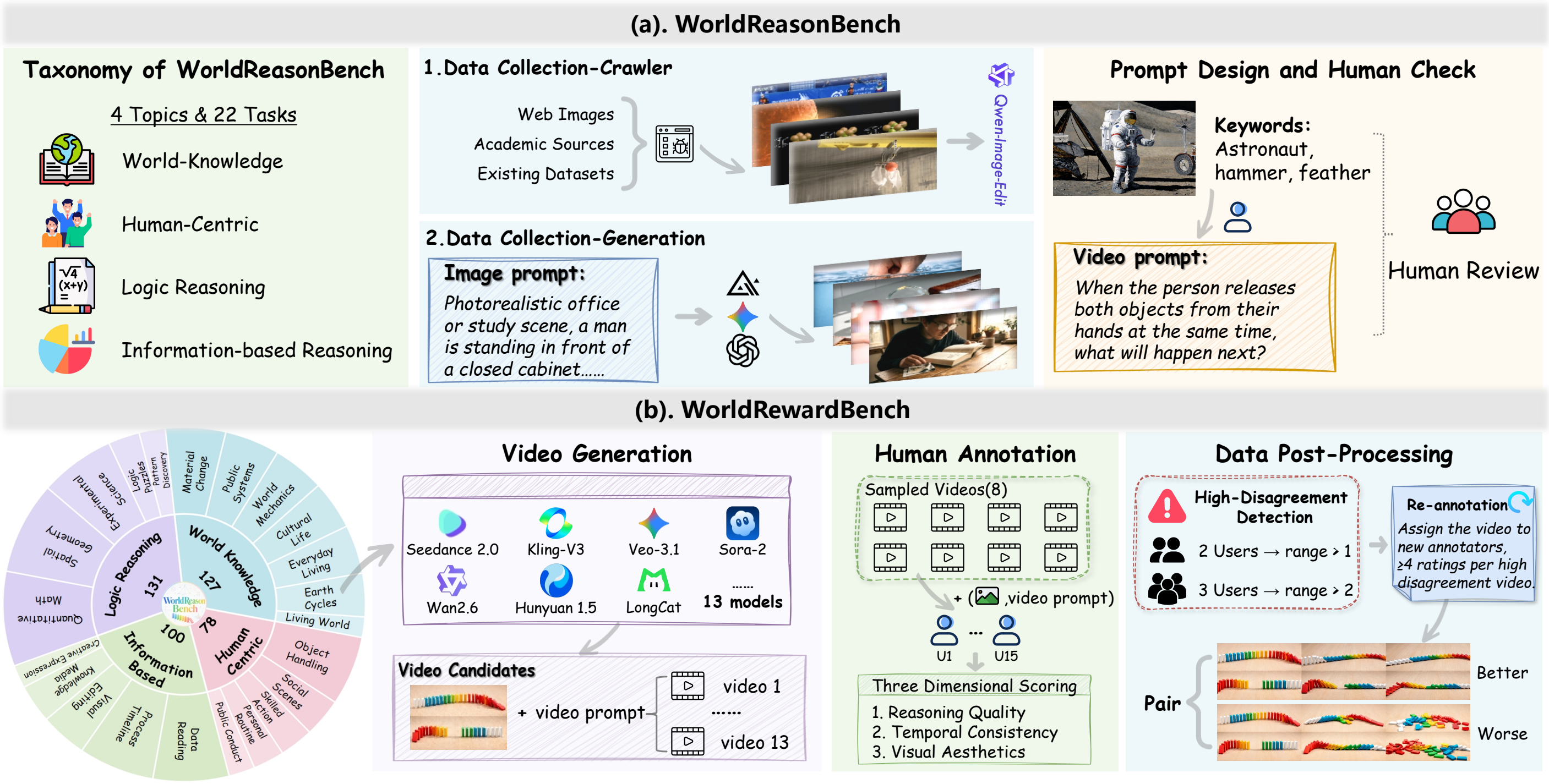
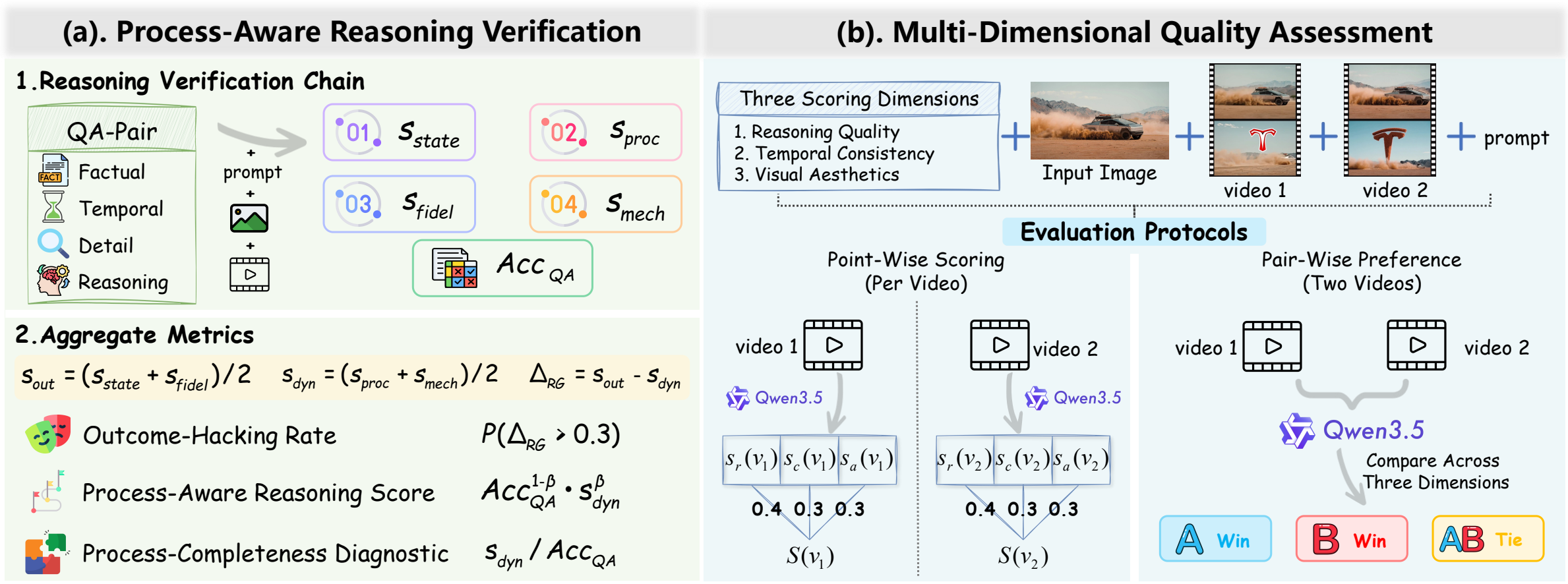
We introduce WorldReasonBench, which reframes video generation evaluation as
world-state prediction: given an initial state and an action, can a model generate a
future video whose state evolution remains physically, socially, logically, and informationally
consistent? It contains 436 curated test cases with structured ground-truth QA
annotations spanning four reasoning dimensions and 22 subcategories.
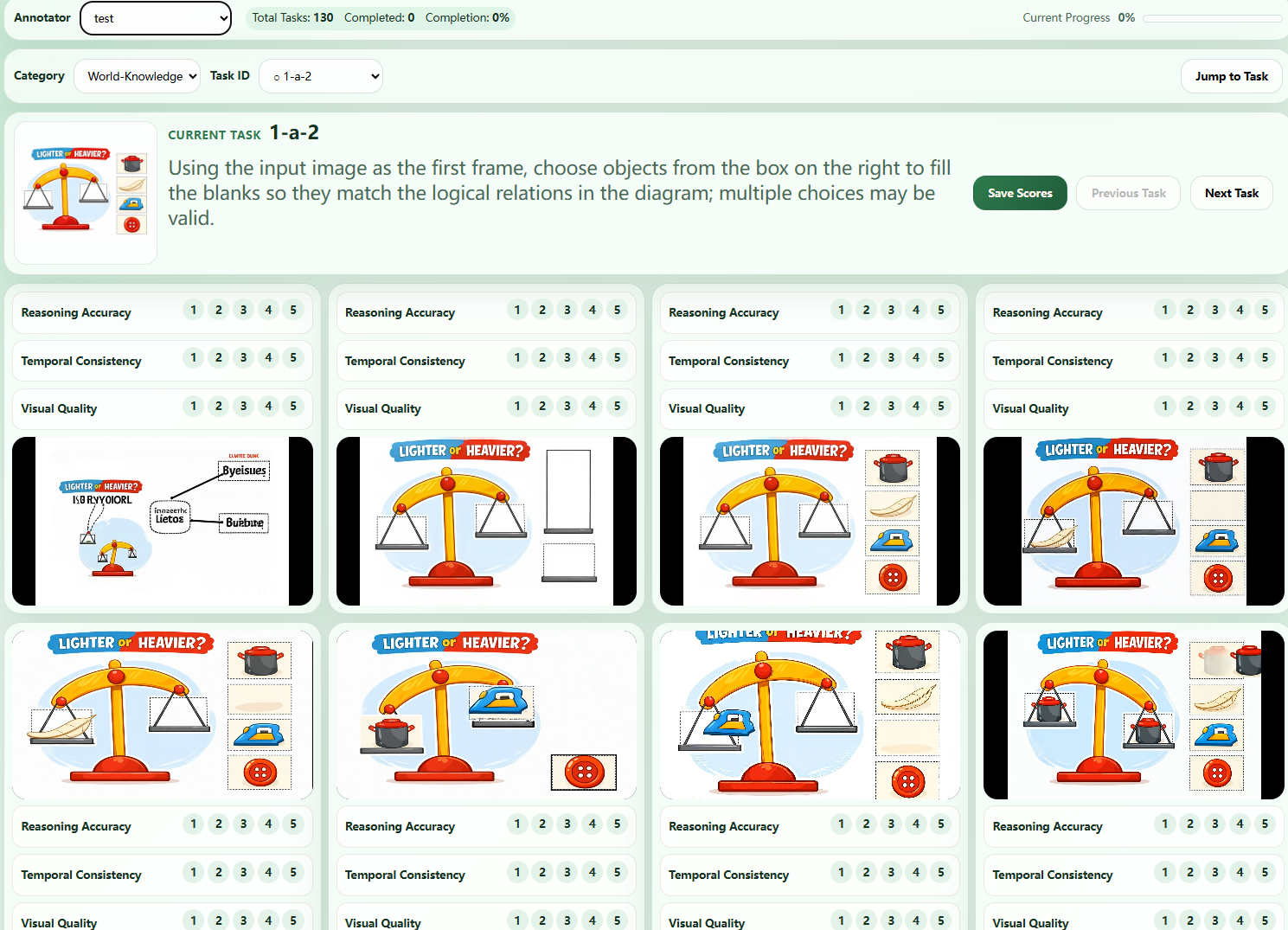
We further release WorldRewardBench, a preference benchmark with approximately
6K expert-annotated pairs over 1.4K videos, supporting pair-wise and point-wise
reward-model evaluation.